Proyecto 1: Exploración de Datos
El objetivo de este proyecto es realizar un primer análisis exploratorio sobre un dataset, partiendo de la importación de las bibliotecas necesarias para la exploración y descripción de los datos. Para este análisis se utilizan las bibliotecas Pandas, Numpy, Seaborn y MatplotLib.

Proyecto 2: Limpieza y Transformación de Datos
El objetivo de este proyecto es continuar con la limpieza de datos, aplicando diferentes técnicas para remover valores faltantes y outliers, también agregar nuevos atributos al DataFrame.
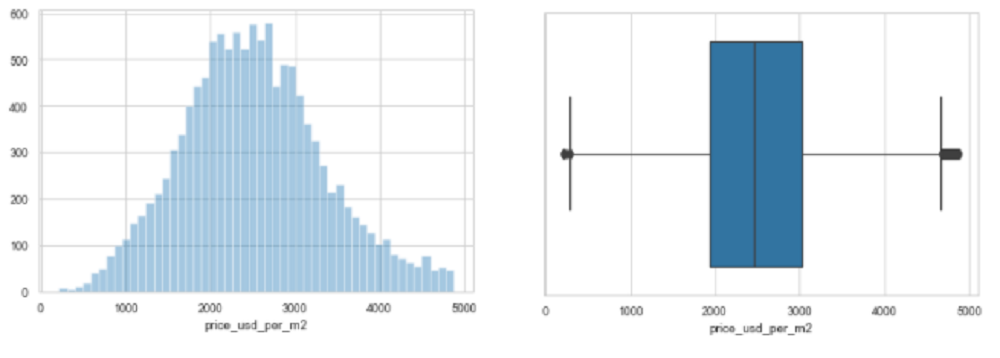
Proyecto 3: Predicción del Precio de Propiedades
El objetivo general de este proyecto es armar un modelo sencillo para predecir el precio de propiedades en dólares, utilizando DecisionTreeRegressor y KNeighborsRegressor de Scikit-learn. El objetivo específico es lograr mayor precisión en la predicción del modelo, para ello se trabaja en el ajuste de los parámetros y su evaluación. La métrica utilizada es RMSE (raíz del error cuadrático medio) y se trabaja sobre un Dataset sobre propiedades a la venta, el cual ya ha sido limpiado.
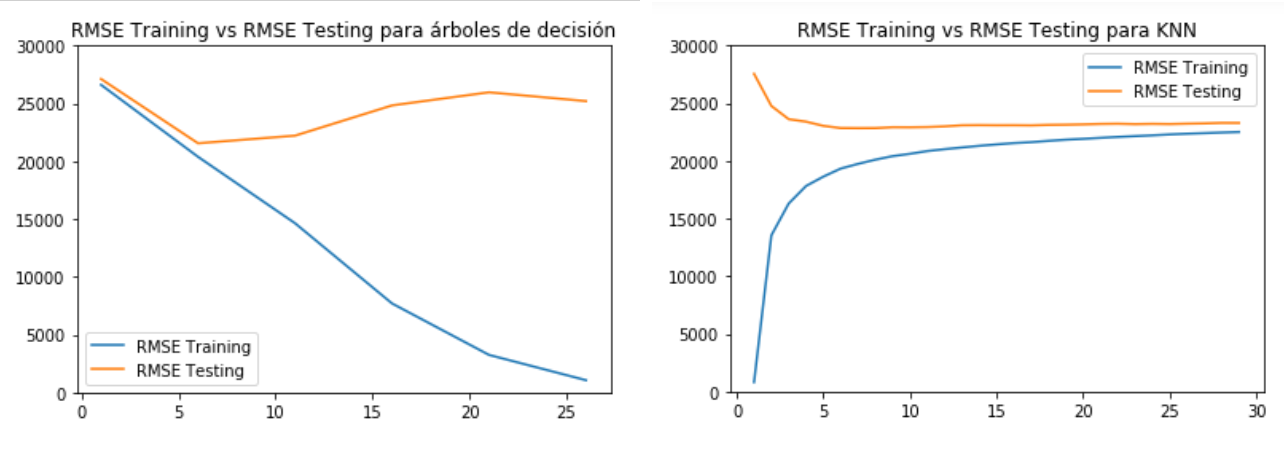
Proyecto 4: Optimización de Parámetros
El objetivo de este proyecto corto se centra en optimizar los parámetros sobre el modelo Decision Tree utilizado en el proyecto Modelos de Predicción, por ello se sigue trabajando con el dataset filtrado y transformado a partir de los datos de propiedades en venta publicadas en el portal Properati. Se utiliza el RMSE (raíz del error cuadrático medio) como métrica.

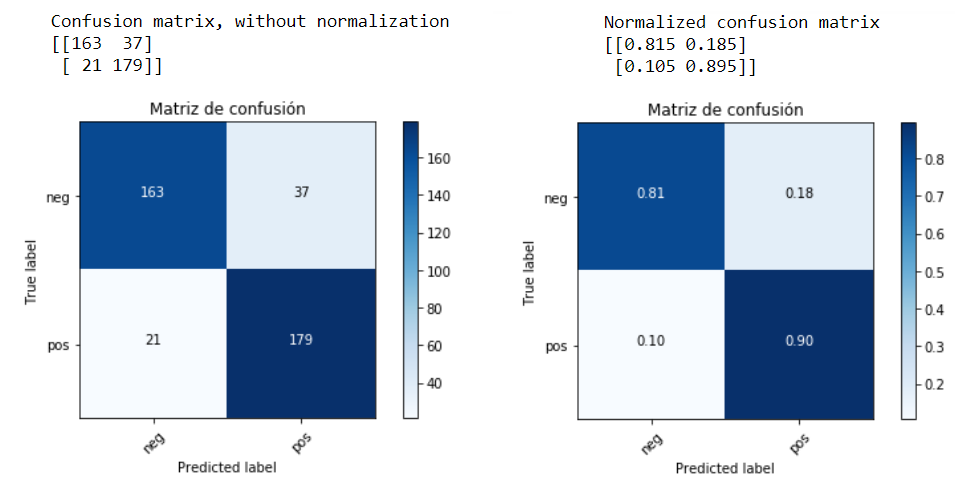
Proyecto 5: Análisis y Clasificación de Sentimientos
El objetivo de este proyecto, es realizar una clasificación de comentarios de acuerdo al sentimiento positivo o negativo expresado en ellos. El análisis se realiza en un conjunto de datos sobre reviews de películas y se trabaja con procesamiento de texto para luego aplicar diferentes técnicas predictivas. En este caso no se utiliza un archivo ‘.csv’, sino con un directorio estructurado.
Proyecto 6: Sistema de Recomendación
En este proyecto se construye un sistema de recomendación de películas utilizando la librería Surprise para su creación y análisis. Se trabaja sobre el dataset de versión 100k de MovieLens el cual se basa en un sistema de rating de cinco estrellas y texto libre para tags. Contiene 100.000 ratings para 1.682 películas con datos creados por 943 usuarios, los cuales calificaron al menos 20 películas cada uno. Además, se emplean otras librerías como MatPLotLib, Numpy y Collections.
